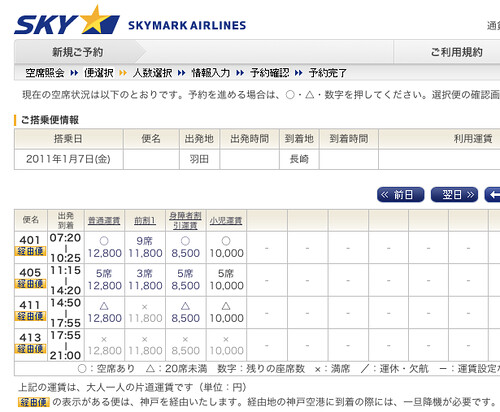
スカイマークエアラインズが、去年の12月から羽田-神戸-長崎便を出すようになったらしい。
28日前予約の最安が長崎、熊本、鹿児島は5,800円、沖縄は7,800円になってる。
実家に帰るときは今までSNA(スカイネットアジア)の割引チケット11,000円-15,000円を買っていたけど、これは28日前に予約を確定しなければいけなかった。僕の場合、ここ数年の帰省はほぼ釣り合宿なので1ヶ月前に状況を予想してチケット取っても、台風とか気候が全く読めなくて泣くことが数知れず。かといって普通料金は35,000円くらいするのでとても手が出なかった。
スカイマークエアラインズは、羽田から神戸で乗り換えて長崎に降りる便になってる。明後日、1月7日の場合、普通運賃が12,800円で、時間と予約状況で変動するようだけど15,000円も出せば好きなときに帰れそう。神戸を経由するのでフライトが180分くらいになるけど(スカイネットは120分)、明日にでも実家に帰れるというのが、ほんとにありがたいです。なくならないで欲しい。
こういうタイミングと予約状況によって運賃が変動していく航空券は、海外ではよくあるらしい。
以前読んだ 「その数学が戦略を決める」 のなかで、こういう航空券の価格変動を予測するForecastの話があった。ワシントン大学の計算機科学教授が、どのタイミングでチケットを買うと安くなるかを予測すべく作ったWebサービスで、いま調べてみたら2年前にMicrosoftに買収されてBing Travelになってた。 マイクロソフト、Farecastを$115Mで買収
その数学が戦略を決める(文庫版) p71
Farecastは予測に115の因子を使い、それを毎日更新して全ての路線に予測を見直す。過去の価格変動だけをみるのではなく、航空券の需要や供給を支える各種の要因 –たとえば燃料価格や気候やフットボールの優勝チームなど– も見ている。スーパーボールの出場選手がかわるだけでも差が出てくる。そしてそこから価格上昇が予測されると上向き矢印、低下が予測されれば下向き矢印が表示される。
いまのところ日本では価格変動しないチケットが多いけど、そのうち変わってくるのでしょう。
日本版のFarecastっぽいものは自分用に作れそうな気がする。
Posted: January 5th, 2011 | Author: yamakk | Filed under: outdoor, 技術, 本 | Tags: farecast, nagasaki, skymark, travel | No Comments »
CentOS5 MacBookPro VMWare
SSH setup
% ssh-keygen -t dsa
% cat ~/.ssh/id_dsa.pub >> authorized_keys
% chmod 600 ~/.ssh/authorized_keys
JDK6 Install
Download http://www.oracle.com/technetwork/java/javase/downloads/index.html
% chmod +x jdk-6u23-linux-i586.bin
% ./jdk-6u23-linux-i586.bin
% sudo cp -r jdk1.6.0_23 /usr/local/jdk1.6.0_23
% sudo ln -s /usr/local/jdk1.6.0_23 /usr/local/jdk
% export PATH=$PATH:/usr/local/jdk/bin
Hadoop Install
% wget http://www.meisei-u.ac.jp/mirror/apache/dist//hadoop/core/hadoop-0.21.0/hadoop-0.21.0.tar.gz
% tar -zxvf hadoop-0.21.0.tar.gz
% sudo cp -r hadoop-0.21.0 /usr/local/hadoop-0.21.0
% sudo ln -s /usr/local/hadoop-0.21.0 /usr/local/hadoop
% export PATH=$PATH:/usr/local/hadoop/bin
Hadoop Setup
/usr/local/hadoop/conf/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
/usr/local/hadoop/conf/core-site.xml
/usr/local/hadoop/conf/hdfs-site.xml
/usr/local/hadoop/conf/mapred-site.xml
Standalone Mode
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Format HDFS
% /usr/local/hadoop/bin/hadoop namenode -format
Start and Kill Hadoop
% /usr/local/hadoop/bin/start-all.sh
% /usr/local/hadoop/bin/stop-all.sh
Start MapReduce
Copy from access_log.txt on local disk to HDFS
% hadoop fs -copyFromLocal access_log.txt /yamakk/log_input.txt
% hadoop fs -ls /yamakk
MapReduce
Sort URLs by number of access
% hadoop jar /usr/local/hadoop/hadoop-mapred-examples-0.21.0.jar grep /yamakk/log_input.txt /yamakk/log_out "GET (\\S+)" 1
check /yamakk/log_out/part-r-00000
Posted: December 30th, 2010 | Author: yamakk | Filed under: 技術 | Tags: hadoop | No Comments »
Scalaの本を立ち読みしてたら面白そうだったので、インストールしてみた。対話モードがあるのがPython使いとしてはとっつきやすそうな気がする。
実利的な目標を設定して勉強すると、だいたいは「Pythonで書いたほうが早いぜ」となって触らなくなるので、言語を楽しむバランスを忘れずにいじろうかと思います。
$ sudo port install scala-27
$ scala-2.7
Welcome to Scala version 2.7.7.final (Java HotSpot(TM) 64-Bit Server VM, Java 1.6.0_22).
Type in expressions to have them evaluated.
Type :help for more information.
object HelloScala{
def main(args : Array[String]){
println(98L-1L)
println("compiled hello")
println("日本語はとおるのか")
}
}
$scalac-2.7 helloc.scala
$scala-2.7 HelloScala
97
compiled hello
日本語はとおるのか
Posted: December 20th, 2010 | Author: yamakk | Filed under: 技術 | Tags: scala | No Comments »
虫の知らせか、4年使っていたDeliciousを先月 Google Bookmarks に移行した。最初 del.icio.us to Google Bookmarks というツールを試したら動かなかったので、Firefoxの機能拡張を使った。いわゆるyak shavingな引越しメモです。
以下のやりかただと、DeliciousでつけたタグはGoogle Bookmarksのラベル(=タグ)に移行できない。ただ、Google Bookmarksの場合Webページの中身の単語を対象に検索できるので、ラベルがなくても困らない。むしろラベルに分けてしまうと、検索対象が自動的にアクティブなラベルに絞られるので、分けない方が使い勝手は良い気がする。
-
Delicious.comからExport / Download Your Delicious Bookmarksでブックマークをexportするdelicious-20101217.htmlのようなファイルがダウンロードできる
-
Firefoxの”Organize Bookmarks”から”Import HTML”を選びdelicious-20101217.htmlをインポートする
-
GMarksをつかって”Organize Gmarks”のメニューからFile>Exportを選びGoogle Bookmarksに同期
だったはず。
今更自分にとって、del.icio.usの何がよかったのだろうと考えたら、名前だったような気がする。deliciousという響きが、多くのユーザに”deliciousなサイト”をブックマークさせていた気がするし、はてなブックマークにネガティブなタグが多いのは、”はてな”という響きもすこしは関係しているのかなと思っている。あくまで無意識のレベルで。
Posted: December 17th, 2010 | Author: yamakk | Filed under: 技術 | Tags: bookmark, delicious, gmarks | No Comments »
iPhoneアプリのデータをとるべくPythonではみんなが使っているUniversal Feed Parserで書き始めたものの、拡張されたnamespaceを操作できないことがわかり、ElementTreeをつかうことにした。
当然できるはずだと思っていたので時間を無駄にした。ドキュメントを読みましょう。
#coding:utf-8
import urllib
from xml.etree import ElementTree
from dateutil import parser as date_parser
def parse_app_feed():
free_url = "http://itunes.apple.com/jp/rss/topfreeapplications/limit=10/xml"
atom_ns = 'http://www.w3.org/2005/Atom'
itunes_ns = 'http://itunes.apple.com/rss'
xml_string = urllib.urlopen(free_url).read()
#xml = ElementTree(file=urllib.urlopen(free_url))
xml = ElementTree.fromstring(xml_string)
xml_updated = date_parser.parse(
xml.find('./{%s}updated' % atom_ns).text)
xml_uri = xml.find('./{%s}id' % atom_ns).text
for e in xml.findall('.//{%s}entry' % atom_ns):
uri = e.find('./{%s}id' % atom_ns).text
name = e.find('./{%s}name' % itunes_ns).text
title = e.find('./{%s}title' % atom_ns).text
category = e.find('./{%s}category' % atom_ns).attrib['term']
description = e.find('./{%s}summary' % atom_ns).text
release_at = date_parser.parse(
e.find('./{%s}releaseDate' % itunes_ns).text)
artist_name = e.find('./{%s}artist' % itunes_ns).text
artist_uri = e.find('./{%s}artist' % itunes_ns).attrib['href']
price = float(e.find('./{%s}price' % itunes_ns).attrib['amount'])
currency = e.find('./{%s}price' % itunes_ns).attrib['currency']
icon_uri = e.findall('./{%s}image' % itunes_ns)[-1].text
screen_uri = [_ent for _ent in e.findall('./{%s}link' % atom_ns) \
if 'image' in _ent.attrib['type']][0].text
print '%s\t%s\t%s' % (name, category, description[:10])
if __name__ == '__main__':
parse_app_feed()
Tapic Games FREE FOR A
! Games テレビ朝日系列「お願
Kozeni Lite Games コインをタップして消
整形マニア Entertainment iPhoneで美容整
Chariso(Bike Rider) Games ☆今だけ無料☆
Find My iPhone Utilities iPhone、iPa
ガイラルディア Games 無料で遊べる王道系の
ZOZOTOWN Lifestyle 日本最大級のファッシ
電卓少女 Entertainment 『電卓少女』で計算萌
Ringtone Maker - Make free ringtones from your music! Music ☆ iPodの中の曲
Posted: November 30th, 2010 | Author: yamakk | Filed under: 技術 | Tags: feed, iphone, itunes, python, rss | No Comments »
式とアルゴリズムが間違っていたので後日修正
オライリーの集合知プログラミングを読んで。迷惑メールをフィルターするのに使われている例が有名。ベイズの定理が分かれば実装はとても簡単。
#coding:utf-8
import re
import math
import MeCab
class NaiveBayes(object):
def __init__(self, spliter):
self.features = {}
self.spliter = spliter
def value(self, category, item):
"""与えられたcategoryのなかで、itemの生起した回数"""
if item in self.features[category]:
return float(self.features[category][item])
return 0.0
def pr_cat(self, category):
""" Pr(category)
与えられたcategoryが選ばれる確率
= 与えられたcategoryのitem数 / 全カテゴリのitem数"""
#疑問 これだと学習量の多いcategoryほど事前確率が大きくなる。それでいいのか?"
return float(sum(self.features[category].values())) \
/ sum([sum(self.features[cat].values()) \
for cat in self.features])
def pr_item_in_cat(self, category, item):
""" Pr(item|category)
与えられたcategoryの中に itemが生起する確率"""
return self.value(category, item) / \
sum(self.features[category].values())
def pr_smooth_item_in_cat(self, category, item,
weight=1.0, default_pr=0.001):
""" あるcategoryにitemがない場合、確率を0にしてしまうのは
極端なので、デフォルト確率と重みを使って調整 """
basic_pr = self.pr_item_in_cat(category, item)
totals = sum([self.value(cat, item) for cat in self.features])
# 単語一つ分 * デフォルト確率 と
# 実際に求めたPr(item|category) * item数を足して
# 単語一つ+item数の数で割る。
# デフォルト確率と単語一つ分を加えた確率の平均を求める
br = ((weight * default_pr) + (totals * basic_pr)) / \
(weight + totals)
return br
def prob_item(self, item):
"""あるitemがあるcategoryに生起する確率
Pr(category|item) ベイズの定理より
= Pr(category AND item) / Pr(item)
= Pr(item|category) Pr(category) / Pr(item)
= Pr(item|category) Pr(category) /
(Pr(item AND category) + Pr(item AND NOT category))
"""
result = {}
for category in self.features:
pr_item_in_cat = self.pr_smooth_item_in_cat(category, item)
pr_cat = self.pr_cat(category)
# Pr(item AND category) = Pr(item|category) * Pr(category)
pr_item_and_cat = pr_item_in_cat * pr_cat
pr_item_and_not_cat = 0
for _category in self.features:
if _category != category:
# Pr(item AND NOT category)
# = Pr(item | NOT category) * Pr(NOT category)
pr_item_and_not_cat += \
self.pr_smooth_item_in_cat(_category, item) * \
(1.0 - pr_cat)
result[category] = pr_item_and_cat / \
(pr_item_and_cat + pr_item_and_not_cat)
return item, result
def prob(self, data):
scores = {}
for item in self.spliter(data):
_item, result = self.prob_item(item)
for cat in result:
scores.setdefault(cat, 0.0)
scores[cat] += math.log(result[cat])
return scores
def train(self, data, category):
items = self.spliter(data)
self.features.setdefault(category, {})
for item in items:
self.features[category].setdefault(item, 0)
self.features[category][item] += 1
def split_mecab(data):
m = MeCab.Tagger('-Owakati')
_data = m.parse(data.encode('utf8'))
items = [s.lower().strip() for s in _data.split(' ')]
return items
if __name__ == '__main__':
nb = NaiveBayes(split_mecab)
# 凧(kaite)と蛸(octopus)について学習させる
nb.train('''凧(たこ)とは風の力を利用して空中に揚げる玩具である。
日本では正月の遊びとして知られている。木や竹などの骨組みに紙、布、ビニー
ルなどを張って紐で反りや形を整えて作られる。''', 'kite')
nb.train('''タコ(蛸、鮹、章魚、鱆、英語名:Octopus)は、頭足綱
- 鞘形亜綱(en)-八腕形上目のタコ目(学名:ordo Octopoda)に分類され
る動物の総称。 海洋棲の軟体動物で、主に岩礁や砂地で活動する。淡水に棲息
する種は知られていない。''', 'octopus')
print '%s,%s' % nb.prob_item('動物')
print '%s,%s' % nb.prob_item('風')
動物,{'octopus': 0.94649122807017538, 'kite': 0.053508771929824568}
風,{'octopus': 0.069298245614035081, 'kite': 0.93070175438596481}
‘動物’が
octopusカテゴリの単語である確率は 94.64%
kiteカテゴリの単語である確率は 5.35%
‘風’が
octopusカテゴリの単語である確率は 6.92%
kiteカテゴリの単語である確率は 93.07%
このような形で文章中の単語ひとつひとつのカテゴリごとの生起確率を計算し、
文章全体がどのカテゴリのものであるかを推測する。
Naive Bayesのアルゴリズムでは1度も出現したことのないitemの確率を
どう重み付け(smoothing)するかによって確率が大きく変わってくるので、注意が必要。
Posted: November 18th, 2010 | Author: yamakk | Filed under: 技術 | No Comments »

昨日図書館で借りてきた。タイトルは熊(クマ)ではなく羆(ヒグマ)
1915年 北海道の三毛別で起きた 三毛別羆事件 をもとに書かれた本。
登場するマタギ「銀オヤジ」の語る羆のTips
火は羆よけにならない
味を覚えると、積極的にヒトを襲う
風上に立つと臭いで気づかれる
撃つときは9m以内の距離で
水(冷たい川を渡るなど)を嫌う
仕留めたら大勢で食べるのが被害者への供養
Posted: October 16th, 2010 | Author: yamakk | Filed under: outdoor, 本 | Tags: クマ, 羆 | No Comments »
既存のSDKを移動
sudo mv /Developer /Developer_xcode_3.2.4_and_ios_sdk_4.1
新しくSDK(xcode_3.2.5_and_ios_sdk_4.2_beta)をインストールする
/DeveloperにインストールされたSDK(xcode_3.2.5_and_ios_sdk_4.2_beta)を移動
sudo mv /Developer /Developer_xcode_3.2.5_and_ios_sdk_4.2_beta
毎度使いたいSDKのシンボリックリンクを/Developerとして作成
ln -s /Developer_xcode_3.2.5_and_ios_sdk_4.2_beta /Developer
シンボリックリンクだとシミュレーターに不具合がでるとの話もあるので
その場合は、mvで/Developerに上書き
mv /Developer_xcode_3.2.5_and_ios_sdk_4.2_beta /Developer
Posted: September 16th, 2010 | Author: yamakk | Filed under: 技術 | Tags: apple, ios, iphone, mac, sdk | No Comments »
rpy2で散布図を書く
import rpy2.robjects as robjects
from rpy2.robjects.packages import importr
grdevices = importr('grDevices')
grdevices.png(file="file.png", width=512, height=512)
# plotting code here
# 月齢
lstx = [0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0,
10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, 17.0, 18.0, 19.0,
20.0, 21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0, 29.0]
# 漁獲高
lsty = [190.0, 200.0, 50.0, 1700.0, 360.0, 620.0, 450.0, 2100.0,
120.0, 5000.0, 1900.0, 780.0, 880.0, 1500.0, 1500.0, 1900.0,
200.0, 270.0, 2100.0, 7000.0, 900.0, 1200.0, 3700.0, 2000.0,
2900.0, 1300.0, 140.0, 2250.0, 120.0, 1000.0]
rx = robjects.FloatVector(lstx)
ry = robjects.FloatVector(lsty)
robjects.r.plot(x=rx, y=ry, xlab="moon age", ylab="fish", col="blue")
grdevices.dev_off()

csvファイルから読み込む場合は、Rの命令文をそのまま書いてもよい
import rpy2.robjects as robjects
from rpy2.robjects.packages import importr
grdevices = importr('grDevices')
grdevices.png(file="file.png", width=512, height=512)
robjects.r('''
data <-read.csv('fish_moonage.csv', header=TRUE)
plot(fish~moonage, xlab="foo", data=data, col="purple")
''')
grdevices.dev_off()
Posted: August 27th, 2010 | Author: yamakk | Filed under: 技術 | Tags: R, python, rpy2, statistics, visualization | No Comments »
Java Library for Amazon EC2がmacbook(mcbk.local)とec2(amazon_ec2)に入っている前提
.zshrc (mcbk.local)
PATH=$PATH:/home/ec2/bin
JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.5.0/Home
EC2_HOME=/home/ec2
EC2_URL=http://ec2.ap-southeast-1.amazonaws.com
.zshrc (amazon_ec2)
PATH=$PATH:/home/ec2/bin
JAVA_HOME=/usr/java/default
EC2_HOME=/home/ec2
EC2_URL=http://ec2.ap-southeast-1.amazonaws.com
キーをec2に転送
AMIファイル作成の準備のためにPublic Key(cert-xxx.pem)とPrivate Key(pk-xxx.pem)をmacbookからec2インスタンスに送る
mcbk.local% scp -i aws/yamakk_amazon_ec2.pem aws/pk-xxxxx.pem aws/cert-xxxx.pem root@ec2:/mnt
AMIファイル20100813_amiをEC2の/mnt上に作成
amazon_ec2# time ec2-bundle-vol \
-d /mnt \
-p 20100813_ami_foo \
--private /mnt/pk-xxxxxxxx.pem \
--cert /mnt/cert-xxxxxxx.pem \
--user 1032-4194-8995 \
-r i386
S3にBucket を作成 (すでに作成している場合は飛ばす)
EC2インスタンスと同じregionを選ばないと非常に遅くなるので注意すること. asia-syngapoleを選択
なぜかec-upload-bundle -r で ap-southeasetを指定しても有効にならずUSに作られるためWebのコンソール https://console.aws.amazon.com/s3/homeから直に作成した。
AMIファイルをS3にアップロード
EC2インスタンスと同じregionを選ばないと非常に遅くなるので、同じregionのS3を選ぶこと (-b の bucket名を確認すること
amazon_ec2# time ec2-upload-bundle \
-r ap-southeast-1 \
-b yamakk/myami/2010-08-13 \
-m /mnt/20100813_ami.manifest.xml \
--access-key xxxxxxxxxxxxxxxxxxxx
--secret-key xxxxxxxxxxxxxxxxxxxx
AMIイメージの登録(MacbookかWebConsoleから作業)
mcbk.local % ec2-register \
--region ap-southeast-1 \
-n 20100813_ami \
yamakk/myami/2010-08-13/20100813_ami.manifest.xml
Posted: August 13th, 2010 | Author: yamakk | Filed under: 技術 | Tags: amazon, ami, ec2, s3 | No Comments »
